Abstract
We propose WayEx, a new method for learning complex goal-conditioned robotics tasks from a single demonstration. Our approach distinguishes itself from existing imitation learning methods by demanding fewer expert examples and eliminating the need for information about the actions taken during the demonstration. This is accomplished by introducing a new reward function and employing a knowledge expansion technique. We demonstrate the effectiveness of WayEx, our waypoint exploration strategy, across six diverse tasks, showcasing its applicability in various environments. Notably, our method significantly reduces training time by 50% as compared to traditional reinforcement learning methods. WayEx obtains a higher reward than existing imitation learning methods given only a single demonstration. Furthermore, we demonstrate its success in tackling complex environments where standard approaches fall short.
Proximal Waypoints
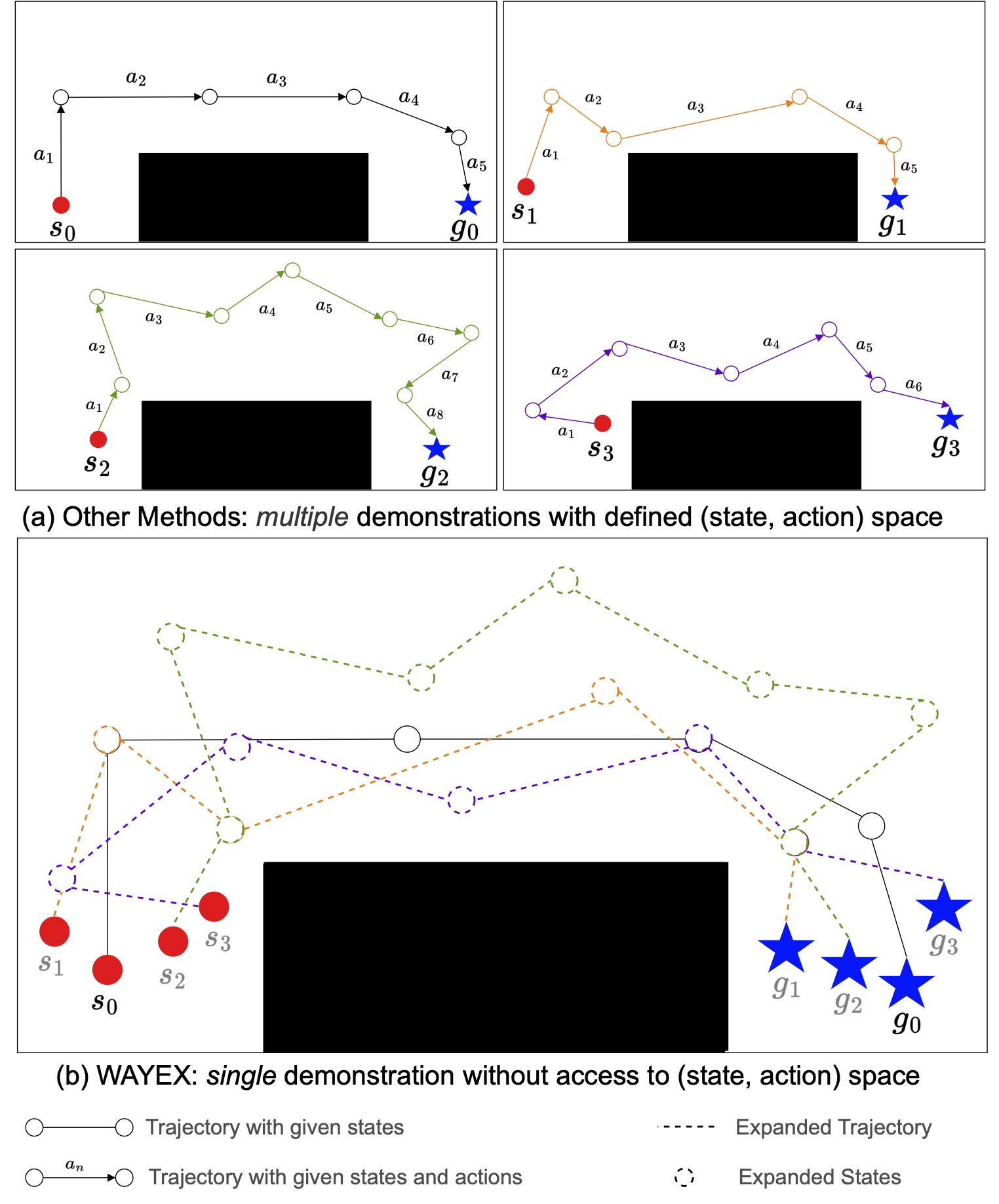
We will use the provided demonstration during training by locating waypoints that are "proximal" to our current state. Two points are considered "proximal" if they fall within a given distance of each other. The two points in the image on the left are considered proximal while the two points on the right are not.
Proximal Reward Function
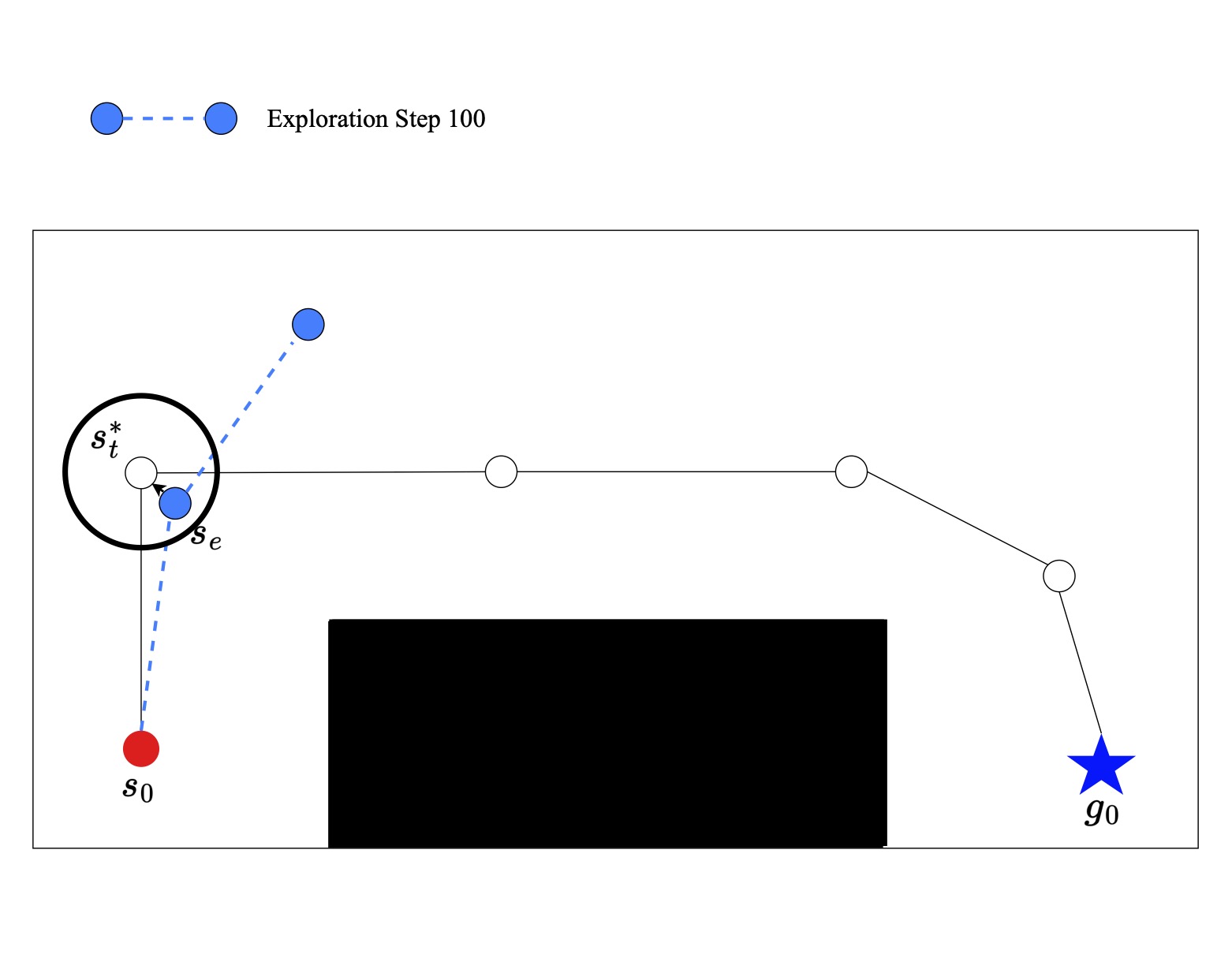
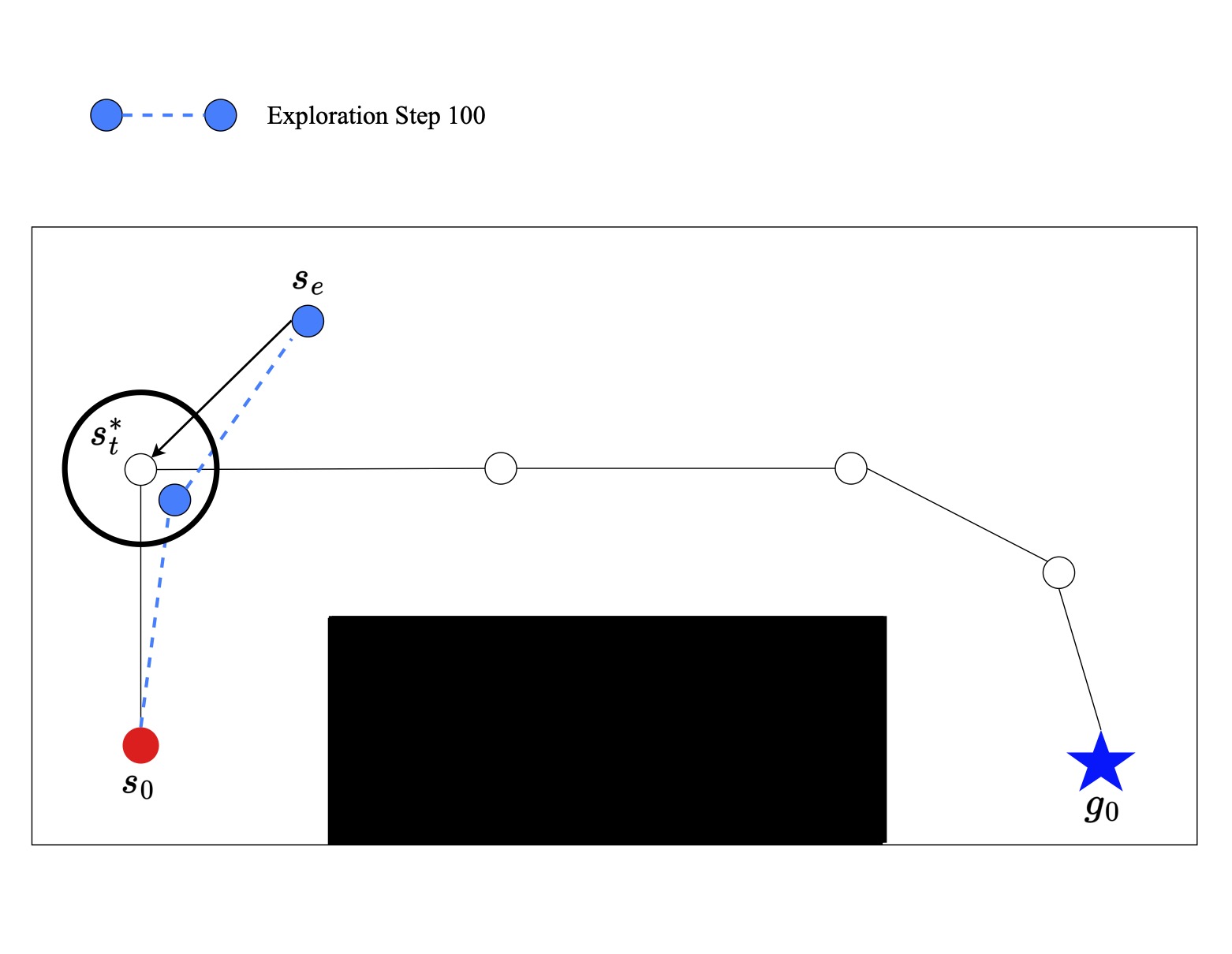
Once we have determined if two points are proximal we can use this information to find the reward for each state during training. We model this reward off a sparse reward. If we assume that if the reward is 0 at the last frame of the expert trajectory and -1 at all other frames we can compute the pseudo ground truth reward for each frame and apply this reward to all proximal waypoints. If the two points are proximal and the waypoint is at step t in an episode of length l the reward is as follows.
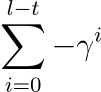
If the two points are not proximal and l max represents the maximum possible length of a demonstration than the reward is as follows.
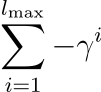
Expansion
When the first part of training is done the policy will have learned how to trace the expert trajectory.
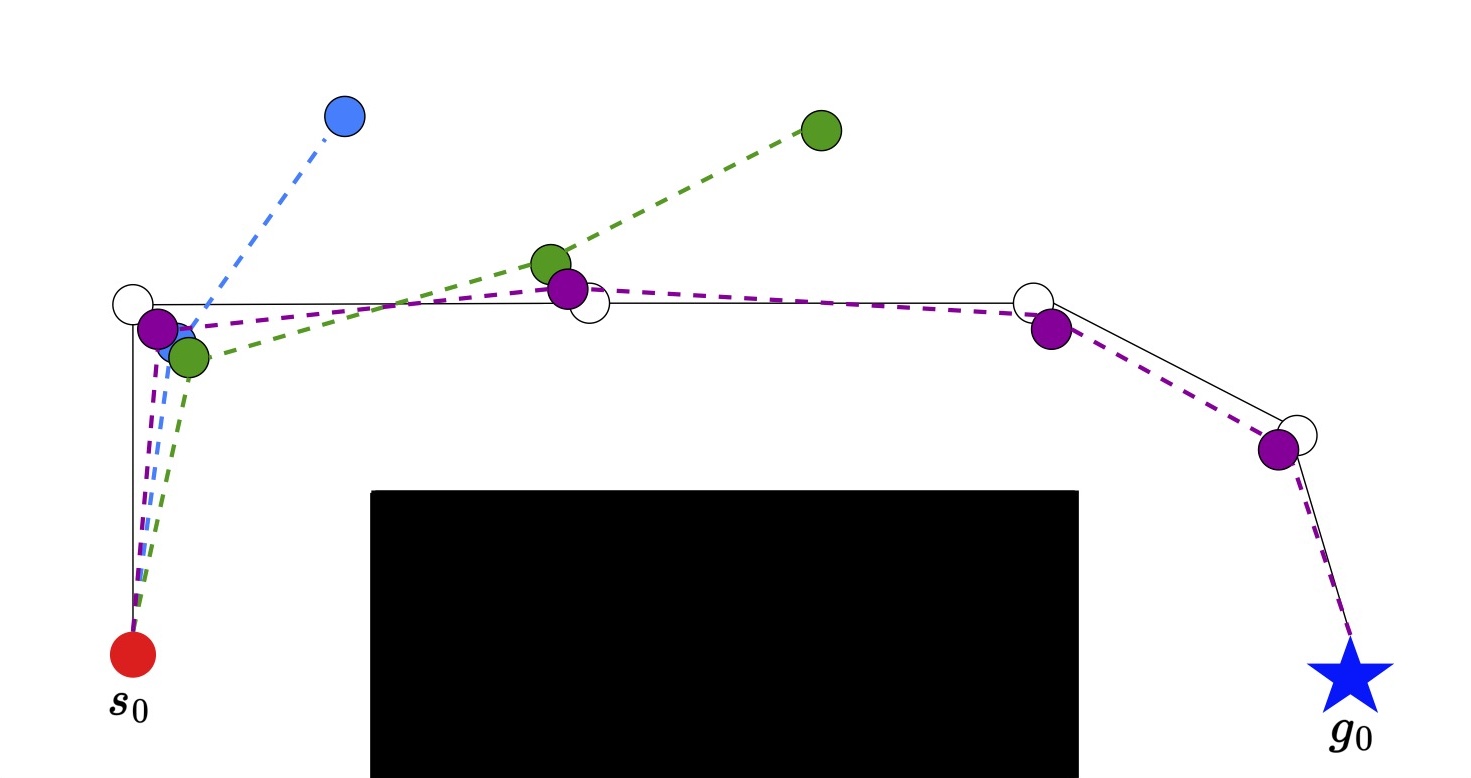
From here we want to expand the policy to cover a larger range of start and end states. We do this by applying increasing amounts of noise to the start and goal state so long as the success rate stays high.
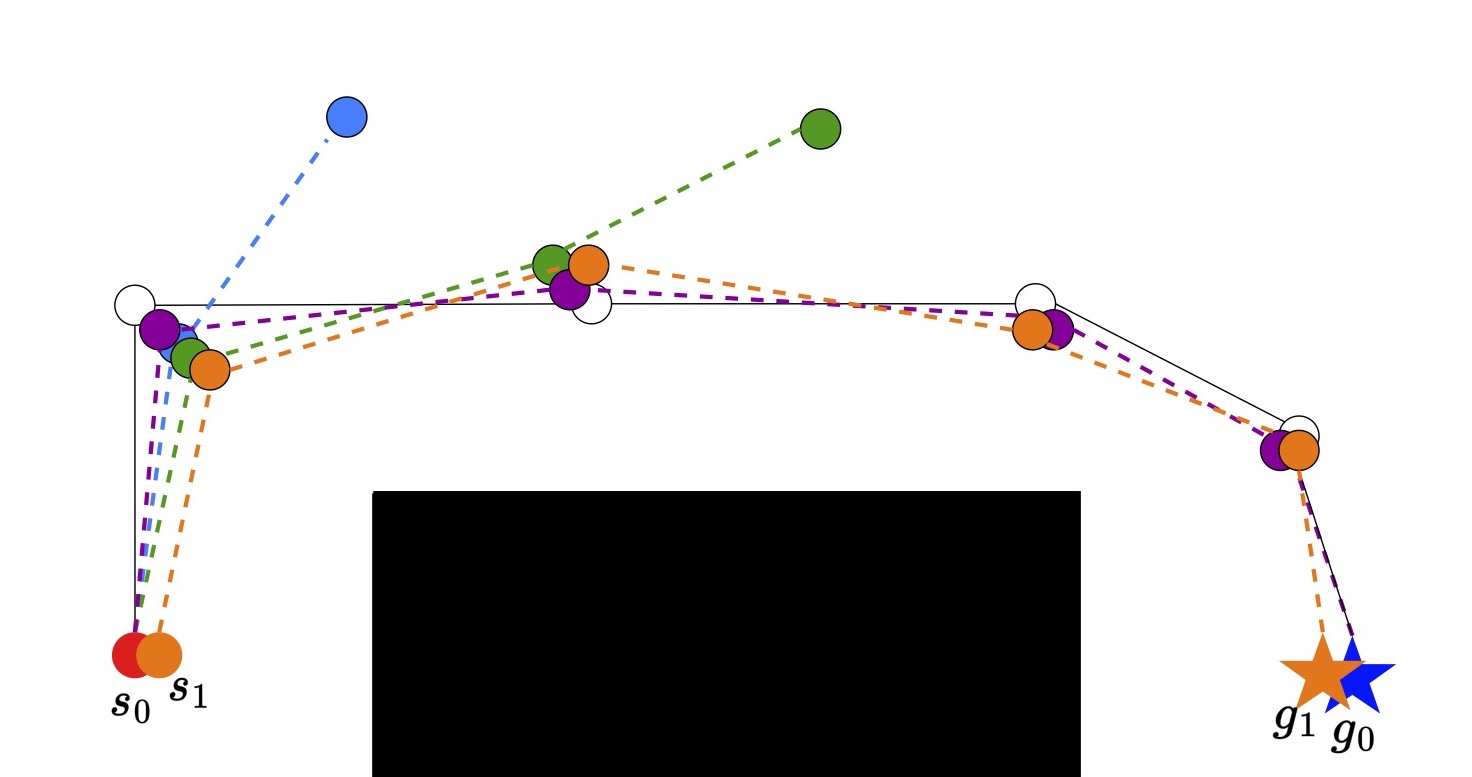
While the first expansion is small eventually we will be able to cover the full range of start and goal states.
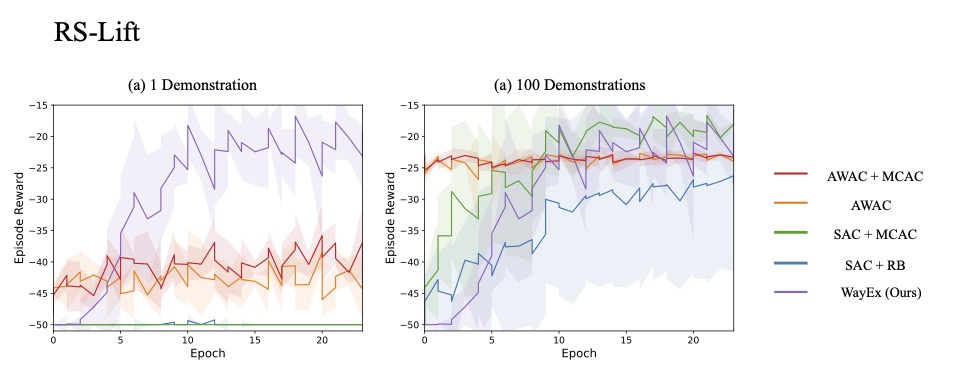
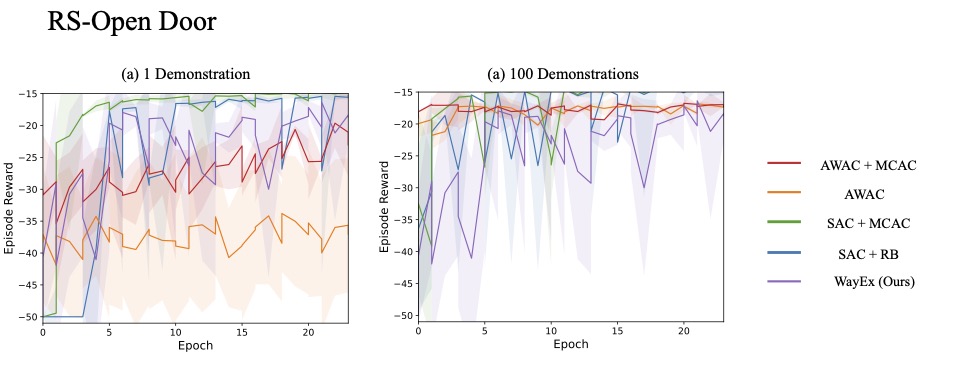
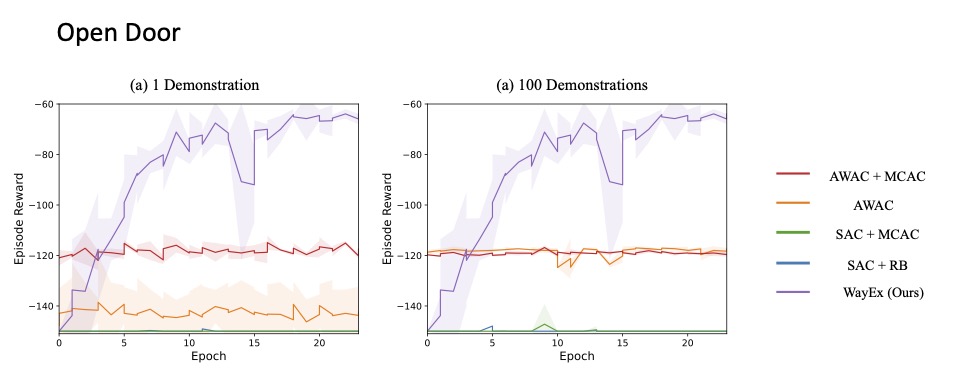
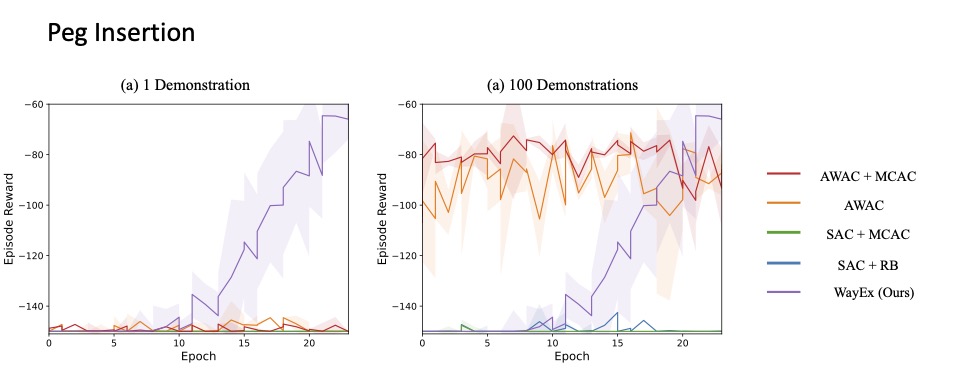
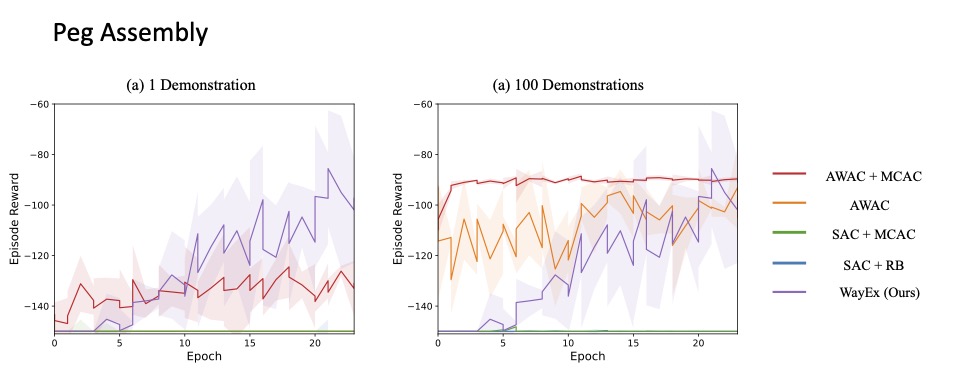
Results